-
(OpenAPI)DATA.GO.KR: OpenAPI로 추출한 데이터 가공 python금융퀀트/프로그램기초 2023. 3. 13. 07:54반응형
데이터 특징파악
"requests"와 "BeautifulSoup" 라이브러리를 이용해서 "기본 URL"에 "내 API키"만 입력해서 데이터에 접근하기 위한 기본적인 코드는 아래와 같다.(자세한 내용은 (OpenAPI)DATA.GO.KR: OpenAPI로 데이터 추출 python 참조)
from bs4 import BeautifulSoup import requests url = "https://apis.data.go.kr/1160100/service/GetMarketIndexInfoService/getStockMarketIndex?serviceKey=" myapikey = "나의 API키" # URL 접근 OpenAPI로 정보 GET res = requests.get(url+myapikey) # 접근 에러 처리 res.raise_for_status() # Beautifulsoup 으로 xml 문서 객체화 soup = BeautifulSoup(res.text, "xml") # print print(soup)아무런 조건도 입력하지 않고 위와 같이 코드를 입력하면 아래와 같은 문서 정보가 print 된다.
<?xml version="1.0" encoding="utf-8"?> <response> <header> <resultCode>00</resultCode> <resultMsg>NORMAL SERVICE.</resultMsg> </header> <body> <numOfRows>10</numOfRows> <pageNo>1</pageNo> <totalCount>119350</totalCount> <items> <item> <basDt>20230309</basDt> <idxNm>IT H/W</idxNm> <idxCsf>KOSDAQ시리즈</idxCsf> <epyItmsCnt>313</epyItmsCnt> <clpr>558</clpr> <vs>-7.4</vs> <fltRt>-1.31</fltRt> <mkp>568.7</mkp> <hipr>569.07</hipr> <lopr>553.6</lopr> <trqu>298028917</trqu> <trPrc>2579878239295</trPrc> <lstgMrktTotAmt>73111541150362</lstgMrktTotAmt> <lsYrEdVsFltRg>76</lsYrEdVsFltRg> <lsYrEdVsFltRt>15.75</lsYrEdVsFltRt> <yrWRcrdHgst>578.89</yrWRcrdHgst> <yrWRcrdHgstDt>20230306</yrWRcrdHgstDt> <yrWRcrdLwst>477.05</yrWRcrdLwst> <yrWRcrdLwstDt>20230102</yrWRcrdLwstDt> <basPntm>19960701</basPntm> <basIdx>1000</basIdx> </item> ... </items> </body> </response>python으로 접근한 이 "금융위원회_지수시세정보"를 바로 사용할 수는 없다. 맨 위의 <numOfRows> 태그와 <pageNo> 태그는 고정으로 "10", "1"이라는 값이 세팅되어서 10개의 데이터만 출력되기 때문이다. 만약 2023-03-09 일자의 온전한 데이터를 뽑으려고 한다면 <numOfRows> 태그나 <pageNo> 태그 부분 조건을 추가적으로 줘야 한다.
조회조건 변경
조건을 어떻게 부여하는지 알아내기 위해서 "개발계정 상세 보기" 화면에서 조건을 부여해서 조회해 보자.
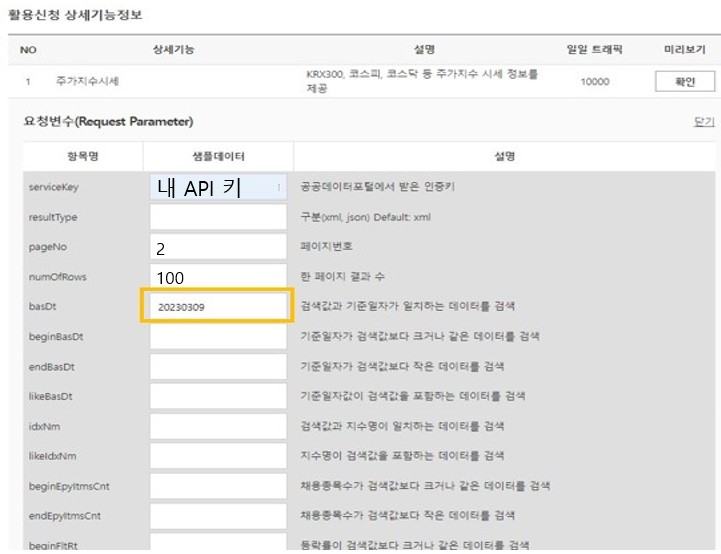
그림1: "개발계정 상세보기" 조건 부여 "미리 보기" 버튼을 누를 때 연결되는 URL을 분석해 보면 아래와 같이 뒤에 "&"를 붙여서 추가 조건을 붙이면 된다는 것을 알 수 있다.
"https://apis.data.go.kr/1160100/service/GetMarketIndexInfoService/getStockMarketIndex?serviceKey=" + "나의 API키" + "&pageNo=2"+ "&numOfRows=100"+ "&basDt=20230309"
결론적으로 2023-03-09 일자의 온전한 데이터를 뽑으려면, 날짜별 최대 페이지 수는 알 수가 없으니 그냥 numOfRows 측 출력 Row의 개수를 1,000 개로 매우 크게 잡아서 데이터를 뽑아내면 된다.
데이터 가공 및 엑셀 변환
pandas 라이브러리 설치
데이터에 어떻게 접근할지 결정했다면 이제 데이터를 어떻게 출력할지 정해야 한다. xml 데이터는 가독성도 떨어지고, 우리에게 익숙한 형식도 아니다. 데이터를 엑셀처럼 가로x세로 형식으로 변경하면 좋은데 그러기 위해서는 데이터를 Dataframe 형식으로 바꿔야 한다.(01 파이썬 데이터 형식(&Pandas 데이터) 참조) Dataframe 은 pandas 라이브러리에서 제공되므로 visual studio 같은 현재 사용하고 있는 에디터 터미널이나 cmd 창에서 아래와 같은 명령어로 pandas를 먼저 설치해 준다.
pip install pandas데이터 구조 확인
글 맨 위의 xml 문서를 잘 보면, 각 종목들이 item 안에 묶여 있고 item 안에서 basDt, idxNm, idxCsf ... 같은 태그로 묶여있는 데이터 구조를 발견할 수 있다. 이 정보를 확인하려면, "(OpenAPI)DATA.GO.KR(공공데이터포털): 데이터 추출"에서 소개한 것처럼 데이터 스펙을 확인해야 한다.
데이터 스펙은 아래와 같이 클릭해서 문서를 다운로드해서 확인할 수 있다.
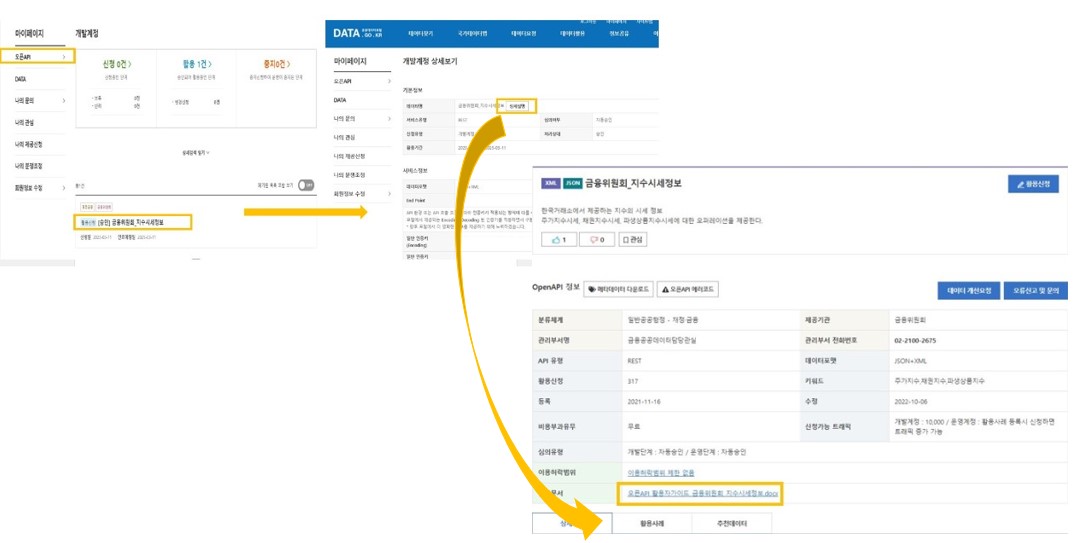
그림2: 데이터 스펙 다운로드 "금융위원회_지수시세정보" 데이터 스펙은 아래에 업로드해 놨으니 참고하기 바란다.
오픈API 활용자가이드_금융위원회_지수시세정보.docx0.35MB데이터 스펙으로 파악한 각 item를 구성하고 있는 태그들의 의미는 아래 그림 3과 같다.

그림3: 데이터 스펙 정리 데이터 정리 및 엑셀 전환
정리하면, 각 item 내부의 각 데이터의 내용(text)이 각 Column 데이터가 되고, 각 item 이 각 Row 데이터가 된다. 따라서 item 전체 덩어리를 items라는 변수에 넣어주고, 각 item 덩어리별 태그 속 데이터를 뽑아내서 데이터 목록을 만든 뒤 Dataframe 변수에 저장하면 excel처럼 가공된 데이터를 얻을 수 있다. 마지막으로 pandas 라이브러리의 to_excel 함수를 사용해서 "public_data.xlsx"라는 파일을 최종적으로 만들면 된다. 이 과정을 코드로 구현하면 아래와 같다.
from bs4 import BeautifulSoup import requests import pandas as pd # 데이터 url 정보 rows = "10000" basedate = "20230309" url = "https://apis.data.go.kr/1160100/service/GetMarketIndexInfoService/getStockMarketIndex?serviceKey=" myapikey = "내 API코드&numOfRows={}&basDt={}".format(rows,basedate) # OpenAPI 데이터 request res = requests.get(url+myapikey) res.raise_for_status() # 빈 데이터 프레임 만들기 data=[] # xml 데이터 객체화 soup = BeautifulSoup(res.text, "xml") # 각 item 묶음들을 items 변수에 넣기 items = soup.find_all("item") # 각 items 안에 있는 컬럼 별 데이터를 list 로 만들어서 빈 data list 에 append for item in items: basdt = item.find("basDt").text idxnm = item.find("idxNm").text idxcsf = item.find("idxCsf").text epyItmsCnt = item.find("epyItmsCnt").text clpr = item.find("clpr").text vs = item.find("vs").text fltRt = item.find("fltRt").text mkp = item.find("mkp").text hipr = item.find("hipr").text lopr = item.find("lopr").text trqu = item.find("trqu").text trPrc = item.find("trPrc").text lstgMrktTotAmt = item.find("lstgMrktTotAmt").text lsYrEdVsFltRg = item.find("lsYrEdVsFltRg").text lsYrEdVsFltRt = item.find("lsYrEdVsFltRt").text yrWRcrdHgst = item.find("yrWRcrdHgst").text yrWRcrdHgstDt = item.find("yrWRcrdHgstDt").text yrWRcrdLwst = item.find("yrWRcrdLwst").text yrWRcrdLwstDt = item.find("yrWRcrdLwstDt").text basPntm = item.find("basPntm").text basIdx = item.find("basIdx").text subdf = [basdt,idxnm, idxcsf, epyItmsCnt, clpr, vs, fltRt, mkp, hipr , lopr, trqu, trPrc, lstgMrktTotAmt, lsYrEdVsFltRg, lsYrEdVsFltRt , yrWRcrdHgst, yrWRcrdHgstDt, yrWRcrdLwst, yrWRcrdLwstDt, basPntm, basIdx] data.append(subdf) # 데이터 프레임 컬럼 지정 df = pd.DataFrame(data,columns=["기준일자", "지수분류명", "지수명", "채용종목수", "종가", "전일대비" , "등락률", "시가", "고가", "저가", "거래량", "거래대금" , "상장시가총액", "전년말대비등락", "전년말등락률","연중기록최고", "연중기록최고일자", "연중기록최저", "연중기록최저일자" , "지수시작일자", "단위"]) # 엑셀로 변환 df.to_excel(excel_writer="public_data.xlsx")반응형'금융퀀트 > 프로그램기초' 카테고리의 다른 글
(OpenAPI)ChatGPT OpenAPI 사용: 기본활용 예제(python) (0) 2023.03.24 (OpenAPI)ChatGPT OpenAPI 사용: API 키 발급 및 요금 (0) 2023.03.22 (OpenAPI)DATA.GO.KR: OpenAPI로 데이터 추출 python (0) 2023.03.13 (OpenAPI)DATA.GO.KR(공공데이터포털): 데이터 추출 (0) 2023.03.11 (OpenAPI)DATA.GO.KR(공공데이터포털): 인증키 발급 (0) 2023.03.11