-
PER PBR 활용05 : DART기업고유번호매핑 및 산업코드 매핑금융퀀트/(퀀트)PERPBR활용 2023. 6. 3. 09:35반응형
"DART기업개황" API 정보 한계
PER PBR 활용04 : 주식 종목 산업분류 데이터 받아오기(DART API)에서 DART 기업고유번호를 입력해서 해당 기업의 산업코드를 알아보았다. 그런데 이렇게 입수한 기업별 산업코드를 활용에 두 가지 문제점이 있다. 먼저 아래 그림 1에 나와 있는 것처럼 기업개황을 보기 위해서 요청할 수 있는 것은 DART의 기업고유번호이다. 우리가 일반적으로 알고 있는 정보는 주식의 종목코드인데 그 주식 종목코드를 기업개황 정보를 요청할 때 포함시킬 수 없는 것이다.
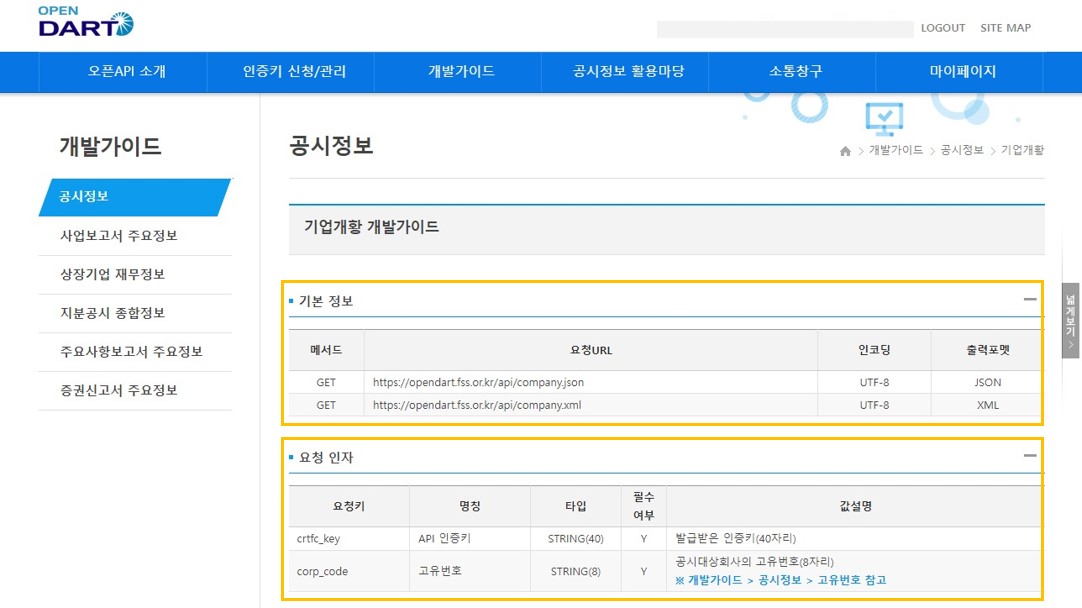
그림1: 기업개황 API parameter 제한 다음으로 아래 그림 2처럼 기업개황 API를 통해서 기업의 산업분류 컬럼을 보면 숫자로 되어 있다. 즉, 기업개황 API만으로는 우리가 해당 기업이 무슨 산업에 속하는지 직관적으로 알 수가 없는 것이다.

그림2: 산업명이 코드로 출력됨 DART 기업고유번호와 주식코드 매핑
DART 기업고유번호와 주식코드 매핑 정보 구하기
주식 종목코드와 DART 기업고유번호를 매핑한 정보가 있다면, "주식 종목코드 -> 매핑 정보-> 기업고유번호 -> DART API 요청" 과정을 통해서 DART 기업고유번호를 API parameter에 포함시킬 수 있다. 위 그림 1 하단 "고유번호"에 대한 설명에서 "※ 개발가이드 > 공시정보 > 고유번호"라는 설명을 참조하여 경로를 따라가면 아래 그림 3과 같은 매핑 정보를 찾을 수 있다.

그림3: 고유번호, 주식종목코드 매핑 정보 찾기 아래 그림 4는 기업고유정보와 주식종목코드를 매핑한 정보(고유정보)의 개발가이드다. 아래 그림 4에서 확인할 수 있는 것처럼 출력포맷이 Zip File이므로 python에서 API 요청해서 데이터를 사용할 수는 없고, 제공되는 URL에 요청인자를 붙여서 ZIP 파일을 다운로드하여서 정보를 이용할 수 있다.

그림4: 고유번호 데이터 제공 구조 아래 그림 5와 같이 "요청URL?crtfc_key=나의 API 키"로 URL을 조립해서 브라우저에 입력하면 자동으로 파일이 다운로드되는 것을 확인할 수 있다. 주의해야 할 점은 "chrome, edge는 브라우저 특성상 ZIP파일이 아닌 xml파일로 다운로드되므로, 확장자명을 ZIP으로 바꾸시면 정상적으로 확인하실 수 있습니다."라고 나와 있으니 해당 브라우저 사용자는 확장자를 바꾼 뒤 ZIP 파일 압축을 풀어야 한다.

그림5: 고유번호, 주식코드 매핑 데이터 다운로드 주식종목코드를 이용해서 DART기업고유번호 추출하기
압축을 풀면 아래와 같은 xml 파일 내용을 확인할 수 있다. 전체 결과가 <result></result> tag로 감싸져 있고 개별 종목에 대한 정보가 <list></list> tag로 감싸져 있다. <list></list> tag 속에 <stock_code>가 6 자리로 된 주식 종목코드이고 <corp_code>가 DART기업고유번호이다.
<?xml version="1.0" encoding="UTF-8"?> <result> <list> <corp_code>00434003</corp_code> <corp_name>다코</corp_name> <stock_code> </stock_code> <modify_date>20170630</modify_date> </list> ...(중략)... <list> <corp_code>00126380</corp_code> <corp_name>삼성전자</corp_name> <stock_code>005930</stock_code> <modify_date>20230110</modify_date> </list> ...(후략)... </result>지금까지 파악한 정보를 바탕으로 다운로드 한 데이터를 DataFrame으로 만들어 주는 configCorpCodeMap이라는 함수를 아래와 같이 만들어 볼 수 있다.
import pandas as pd from bs4 import BeautifulSoup path = "다운로드한 파일 경로" # 다운로드 한 파일 경로를 변수로 받는 configCorpCodeMap 함수 def configCorpCodeMap(file_path): # 빈 list 만들기 df = [] # read 로 파일 열고 xml_data 라는 변수에 저장 with open(file_path, "r", encoding="utf-8") as file: xml_data = file.read() # 파싱을 위해서 BeautifulSoup 객체로 저장 soup = BeautifulSoup(xml_data, "lxml") # 각 list tag 를 list 변수에 저장 for list in soup.find_all("list"): # 각 list tag 안에서 corp_code 를 corp_code 변수에 저장 corp_code = list.find("corp_code").text # 각 list tag 안에서 stock_code 를 stock_code 변수에 저장 stock_code = list.find("stock_code").text # 주식코드가 6 자리로 유효하면 mapping list 에 추가 if len(stock_code) == 6: df_if = [corp_code, stock_code] df.append(df_if) else: pass # 완성된 데이터 list 로 DataFrame 구축 df = pd.DataFrame(df, columns=["DART코드", "주식코드"]) return df최종적으로 configCodeMap에서 만든 데이터프레임과 주식코드를 변수로 받아서 DART 기업고유번호를 출력하는 getCorpCode 함수를 아래와 같이 만들 수 있다.
# DART코드와 주식코드를 매핑한 DataFrame 과 주식코드를 변수로 받는 getCorpCode 함수 def getCorpCode(df: pd.DataFrame, stockcode:str): # 입수된 DaraFrame 의 주식코드 컬럼과 입수된 주식코드가 같으면 같은 row의 DART코드 출력 corpcode = df.loc[df["주식코드"]==stockcode,"DART코드"].values[0] return corpcode산업코드와 산업코드명 매핑
DART 에서 제공하는 기업별 업종코드 체계
주식코드와 DART기업고유번호를 매핑한 것처럼 산업코드도 산업코드명과 매핑할 수 있는 데이터가 있다면 산업코드 명을 확인할 수 있다. OpenDART 사이트 내에서 매핑 기준은 명확하게 제시되어 있지 않고, 아래 그림 6과 같이 공식 Q&A를 통해서 한국표준산업분류 코드라는 것을 확인할 수 있었다.(https://kssc.kostat.go.kr:8443/ksscNew_web/link.do?gubun=001#)

그림6: 금융감독원 표준산업코드 답변 아래 그림 7과 같이 위 그림 6의 링크(https://kssc.kostat.go.kr:8443/ksscNew_web/link.do?gubun=001#) -> 자료실 -> 최신개정 부분에 들어가 보면 표준산업분류표를 다운로드할 수 있다.

그림7: 한국표준산업분류표 다운로드 표준산업분류표를 열어보면 아래 그림 8과 같이 되어 있는데, 중간 레벨인 소분류를 사용하면 된다. 정리하면 우리가 필요한 데이터는 그림 8 엑셀의 E~F 열 & 3행 밑으로 있는 데이터이다.

그림 8: 표준산업분류표 데이터 구조 업종코드를 이용하여 업종코드명 추출하기
지금까지 파악한 정보를 바탕으로 다운로드 한 데이터를 아래 코드를 통해서 DataFrame으로 만들어 주는 configIndustMap이라는 함수를 아래와 같이 만들 수 있다.
import pandas as pd path = "파일 저장 경로" # 파일경로를 변수로 받아서 산업분류, 산업분류코드명을 가진 DataFrame 을 만들어주는 함수 def configIndustMap(file_path): # 엑셀 파일 형식 read 해서 data 변수에 저장 data = pd.read_excel(file_path) # 데이터에서 필요한 부분만 뽑아내고, n/a 인 데이터 row 삭제 data = data.iloc[2:,4:6].dropna() # 데이터 컬럼 설정 data.columns = ["산업코드","산업코드명"] # data 객체를 DataFrame 형식으로 변환 df = pd.DataFrame(data) # index 재설정 df.reset_index(drop=True, inplace=True) return df최종적으로 configIndustMap에서 만든 데이터프레임과 산업코드를 변수로 받아서 산업코드명을 출력하는 getIndustName 함수를 아래와 같이 만들 수 있다.
# 산업코드와 산업코드명을 매핑한 DataFrame 과 산업코드를 변수로 받는 getIndustName 함수 def getIndustName(df, industcode:str): # 입수된 DaraFrame 의 산업코드컬럼과 입수된 산업코드가 같으면 같은 row의 산업코드명 출력 industname = df.loc[df["산업코드"]==industcode, "산업코드명"].values[0] return industnamegetIndustName 함수에 위 그림 2에서 나온 "264"라는 산업코드를 입력하면 아래 그림 9와 같이 산업코드명이 잘 출력되는 것을 확인할 수 있다.

그림 9: 산업코드명 출력 결과 반응형'금융퀀트 > (퀀트)PERPBR활용' 카테고리의 다른 글
PER PBR 활용07 : 기업별 산업코드 PER PBR 데이터 생성 프로그램 구조 (2) 2023.06.13 PER PBR 활용06 : 기업별 산업코드 PER PBR 데이터 생성 프로그램 CLASS 구성 (0) 2023.06.10 PER PBR 활용04 : 주식 종목 산업분류 데이터 받아오기(DART API) (0) 2023.06.02 PER PBR 활용03 : 주식별 PER PBR 목록 만들기 (0) 2023.06.01 PER PBR 활용02 : 주식목록 입수(공공데이터API) (0) 2023.05.31