-
파이썬: 멀티쓰레딩을 활용한 기업기본정보 목록 만들기(DART API활용)금융퀀트/프로그램기초 2024. 3. 17. 09:52반응형
멀티쓰레딩풀 활용의 필요성
파이썬: 멀티쓰레딩(Threading)과 멀티프로세싱(multiprocessing) 에서 살펴본 것처럼 단일 함수들의 멀티쓰레딩, 멀티프로세싱은 단순히 구현하면 되지만 함수가 복잡하거나, 수많은 작업을 다시 작은 단위로 묶어서 작업하고 싶을 때(총작업량은 1만 개인데, 100개씩 한 번에 처리하고 싶을 때)는 단순한 멀티쓰레딩이나 멀티프로세싱 구조로는 한계가 있다. 이 경우는 아래의 그림 1처럼 쓰레딩 또는 프로세싱 작업묶음의 풀을 만들어서 해결할 수 있다.

그림1: 작업 풀 만드는 구조 작업풀에 작업묶음1, 2, 3을 동시에 넣고 작업을 수행한 뒤 결과를 한 번에 뽑아내는 방식이다. 멀티쓰레딩과 멀티프로세싱 모두 작업풀로 처리가 가능하지만 이하에서는 멀티쓰레딩풀만을 이용하여 API를 요청한 결과를 가지고 기업기본정보 목록을 만드는 것을 구현해 보겠다.
기업코드 리스트 받기
금융감독원 공시 사이트 다트는 API 호출로 손쉽게 데이터를 받아볼 수 있도록 OPEN DART서비스를 지원하고 있다.((OpenAPI)DART Open API 사용법1: 인증키 발급 참조) OPEN DART 서비스에서 기업들은 우리가 흔히 아는 주식종목코드(ex. 삼성전자: 005930)로 구분되어 있지 않고 DART의 기업코드로 구분되어 있다. 기업코드 리스트는 아래 그림 2의 왼쪽과 같은 그림을 통해서 들어가면 그림 2의 우측에 보이는 매뉴얼을 따라서 받을 수 있다.
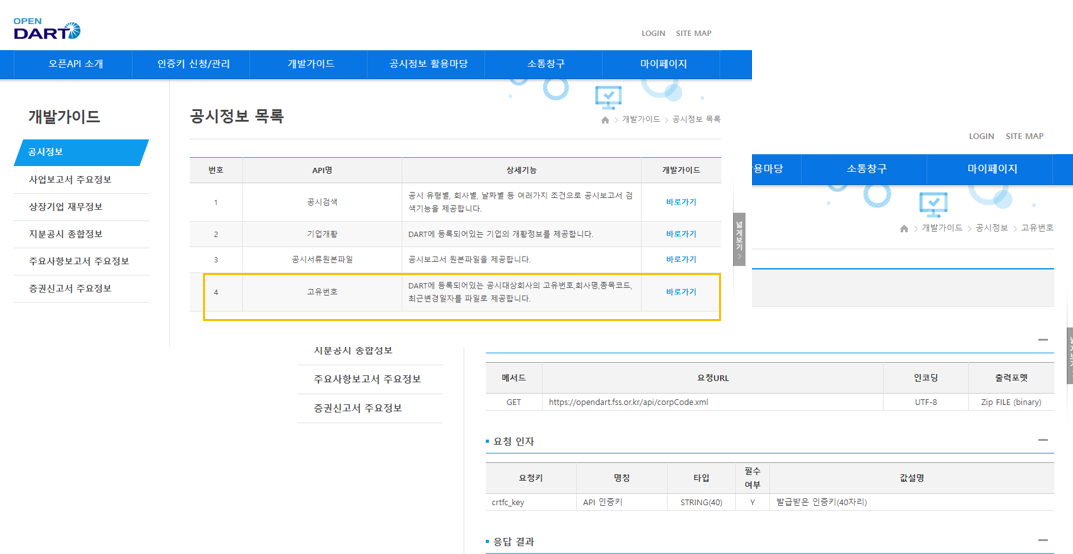
그림2: 기업코드 리스트 받기 가이드가 복잡하게 되어있지만 결국 인터넷 주소창에 아래와 같이 쳐서 접속하면 어떤 파일이 다운되고, 그 파일의 확장자를 zip으로 바꾼 뒤 압축을 풀면 고유번호, 기업명, 주식종목코드가 매핑된 파일을 얻을 수 있다.
https://opendart.fss.or.kr/api/corpCode.xml?crtfc_key=발급받은 나의 다트 API 키 값기업코드 매핑 파일 불러오기: loadmappingfile
OPEN DART 서비스에서 받은 xml 파일을 불러와서 데이터프레임으로 만들어주는 함수가 있다면 기업코드 데이터를 쉽게 활용할 수 있다.
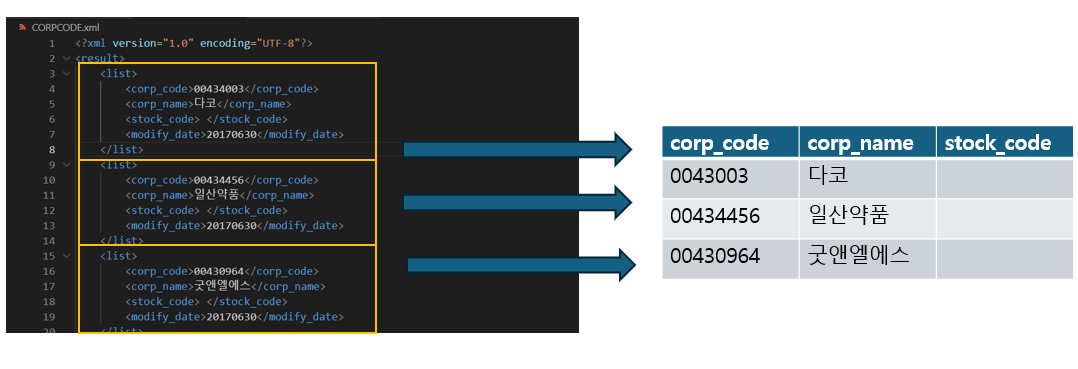
그림3: 기업코드 정보로 데이터프레임 만들기 먼저, 파일을 불러온 뒤 Beautifulsoup 라이브러리를 통해서 불러온 파일의 내용을 soup이라는 객체에 담는다. "list" 단위로 하나의 row를 구성하게 만들고 corp_code, corp_name, stock_code 컬럼으로 이루어진 데이터를 만들어서 row를 계속 추가해 나간 후 마지막에 "기관코드", "기관명", "종목코드"라는 컬럼명을 부여해 준다.
import pandas as pd from bs4 import BeautifulSoup def loadmappingfile(filename: str): # OPEN DART에서 받은 파일 열기 with open(filename, "r", encoding="utf-8") as f: corpcode = f.read() # soup 에 파일 정보 xml 형식으로 담기 soup = BeautifulSoup(corpcode, "xml") data = [] # list 별로 정보를 잘라서 분석 for rows in soup.find_all("list"): # list 하나를 하나의 기업이라고 보고 고유번호, 기업명, 주식코드 정보 저장 row = [] corpcode = rows.find("corp_code").text corpname = rows.find("corp_name").text stockcode = rows.find("stock_code").text if len(stockcode)==6: row = [corpcode, corpname, stockcode] data.append(row) else: pass # 최종 컬럼명을 확정하고 데이터프레임 출력 df = pd.DataFrame(columns=["기관코드", "기관명", "종목코드"], data=data) return dfapi 호출하기: callfssapi
아래 그림 4의 경로로 기업 기본정보를 조회하는 API 매뉴얼을 통해서 손쉽게 API를 요청할 수 있다. 그림 4의 오른쪽을 보면 정보를 얻을 수 있는(GET) url과 API 요청 시 parameter로 입력할 수 있는 값들을 OPEN DART에서 정의해 두었다.
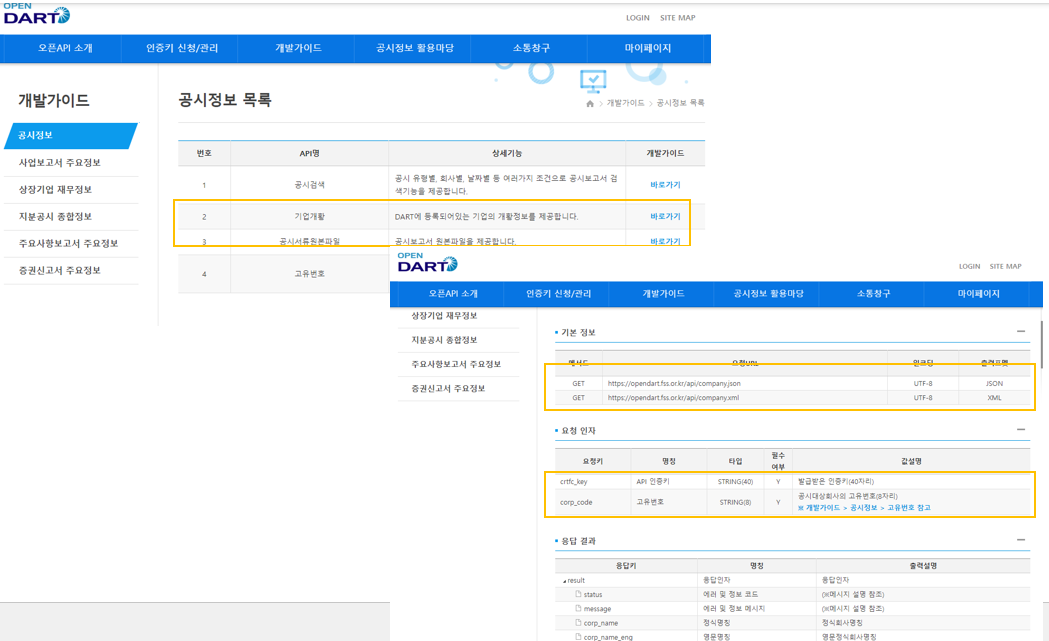
그림4: 기업고유정보 입수 API 사용 고유번호는 callfssapi라는 함수의 변수로 입력받고, 데이터 입수 형식은 json으로 하는 코드는 아래와 같이 작성할 수 있다.
import requests # callfsspai 함수 사용시 corpcode를 입력해 줘야 함 def callfssapi(corpcode: str): dartapikey = "발급받은 나의 다트 API 키 값" # darturl 에 apikey 와 고유번호를 parameter로 입력하여 api호출(json) darturl = "https://opendart.fss.or.kr/api/company.json?" params = { "crtfc_key":dartapikey, "corp_code":corpcode } res = requests.get(darturl, params=params) res.raise_for_status() # 결과를 json 함수를 사용해서 json 형식으로 저장(json으로 요청했으니까) resjson = res.json() return resjson기업기본정보 목록 만들기: getcorpbasic
api로 요청한 결과는 아래 그림 5와 같이 알아볼 수 없는 형태로 나오기 때문에 표로 정리할 필요가 있다. 모든 항목을 정리할 수도 있지만 복잡하니까 이하에서는 기업명(corp_name), 대표자명(ceo_nm) 정보 정도만 정리하는 함수를 사용하겠다.
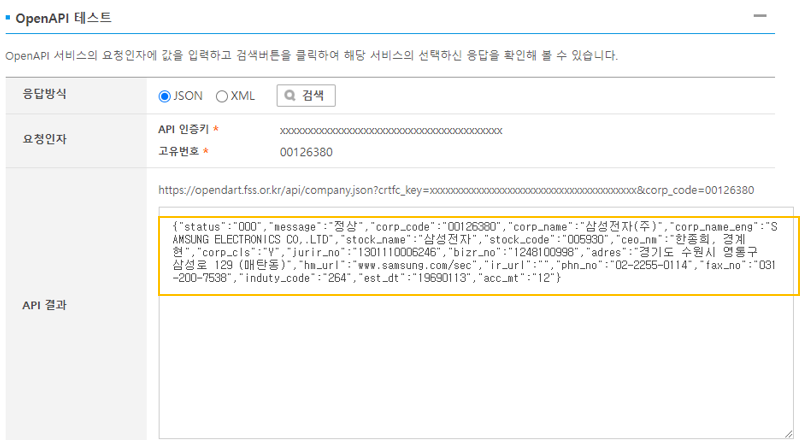
그림5: 기업기본정보 API결과 화면 함수의 구조는 기업코드 매핑파일 불러오는 함수와 크게 다르지 않은데, 먼저 "status"의 결과를 확인하고 결과가 실패를 나타내는 013이 아니라면 "corp_name"과 "ceo_nm" 값을 corpname, ceo라는 변수에 담아서 출력하는 방식이다.
def getcorpbasic(corpcode: str): # callfssapi 함수를 통해서 결과 입수(json형식)해서 data에 저장 data = callfssapi(corpcode) # 응답값 확인 013 일 경우 실패 response = data["status"] if response != "013": # json 데이터의 corp_name, ceo_nm을 corpname, ceo에 저장 후 출력 if data["corp_name"]: corpname = data["corp_name"] ceo = data["ceo_nm"] return corpname, ceo else: pass쓰레드 풀을 활용한 api호출 작업
멀티쓰레드 풀을 활용한 작업은 concurrent.futures 라이브러리를 통해서 할 수 있다. ThreadPoolExecutor에서 pool에 들어갈 최대 작업 수를 지정해 놓고, 요청작업을 한다. 변수에(futures) 요청작업을 리스트 형태로 저장하고, 요청작업별 결과를 변수에(results) 리스트 형태로 저장하고 출력한다.
import concurrent.futures as multitr def multithredwork(): # 고유번호 목록을 고유번호 파일에서 10개만 뽑음 corpcodes = loadmappingfile("CORPCODE.xml")["기관코드"][0:10] # 최대 작업 11개로 만들고 "멀티쓰레딩 작업"을 executor 로 변수화 with multitr.ThreadPoolExecutor(max_workers=11) as executor: # 요청 작업 리스트 만들기(furures) futures = [] # 고유번호 목록들을 하나씩 corpcode변수에 넣고 getcorpbasic 함수를 실행 for corpcode in corpcodes: future = executor.submit(getcorpbasic, corpcode) # 요청들을 하나씩 요청작업 리스트에 넣기 futures.append(future) # 결과 리스트 만들기(results) results = [] # 요청리스트들에서 완료된 작업(as_completed)을 future 변수에 입수 for future in multitr.as_completed(futures): # 요청에 대한 결과를 입수 result = future.result() # 결과 리스트에 개별 결과를 입수 results.append(result) # 결과 출력 print(results)전체 코드는 아래와 같이 정리할 수 있고 그 결과도 아래와 같이 확인 가능하다.
import concurrent.futures as multitr import requests import pandas as pd from bs4 import BeautifulSoup # 스레드로 실행될 함수 정의 def callfssapi(corpcode: str): dartapikey = "발급받은 나의 다트 API 키 값" darturl = "https://opendart.fss.or.kr/api/company.json?" params = { "crtfc_key":dartapikey, "corp_code":corpcode } res = requests.get(darturl, params=params) res.raise_for_status() resjson = res.json() return resjson def loadmappingfile(filename: str): with open(filename, "r", encoding="utf-8") as f: corpcode = f.read() soup = BeautifulSoup(corpcode, "xml") data = [] for rows in soup.find_all("list"): row = [] corpcode = rows.find("corp_code").text corpname = rows.find("corp_name").text stockcode = rows.find("stock_code").text if len(stockcode)==6: row = [corpcode, corpname, stockcode] data.append(row) else: pass df = pd.DataFrame(columns=["기관코드", "기관명", "종목코드"], data=data) return df def getcorpbasic(corpcode: str): data = callfssapi(corpcode) response = data["status"] if response != "013": if data["corp_name"]: corpname = data["corp_name"] ceo = data["ceo_nm"] return corpname, ceo else: pass # 멀티쓰레딩 수행하는 코드 def multithredwork(): corpcodes = loadmappingfile("CORPCODE.xml")["기관코드"][0:10] results = [] with multitr.ThreadPoolExecutor(max_workers=11) as executor: futures = [] for corpcode in corpcodes: future = executor.submit(getcorpbasic, corpcode) futures.append(future) results = [] for future in multitr.as_completed(futures): result = future.result() results.append(result) print(results) # 위에서 정의된 함수들로 작업 수행 multithredwork()
그림6: 최종 작업 결과 반응형'금융퀀트 > 프로그램기초' 카테고리의 다른 글
(OpenAPI)KRX OpenAPI 활용: 서비스 이용 신청 및 API 예제 (2) 2024.03.28 (OpenAPI)KRX OpenAPI 활용: 인증키 발급 (0) 2024.03.23 파이썬: 멀티쓰레딩(Threading)과 멀티프로세싱(multiprocessing) (0) 2024.03.16 파이썬 : 함수(Function), 클래스(Class), 모듈(Module), 패키지(Package) (0) 2024.01.31 [AWS]RDS 서버 만들기 (1) 2024.01.12