-
파이썬 : 웹스크레핑 홈페이지 구조파악(네이버파이낸스)금융퀀트/프로그램기초 2021. 7. 4. 21:48반응형
검사기능 이해
인터넷에서 데이터를 끌어오려면 인터넷의 문서들이 어떻게 생겨먹은지를 알아야 한다. 우리가 접하는 화면을 넘어서 홈페이지의 속 뼈대를 파악해야 실제 인터넷 문서들에서 데이터를 끌어올 수 있다. 우리가 사용하는 대부분의 익스플로러에서 홈페이지의 속 모습을 파악할 수 있는 기능을 제공하는데 그것이 "검사" 기능이다.
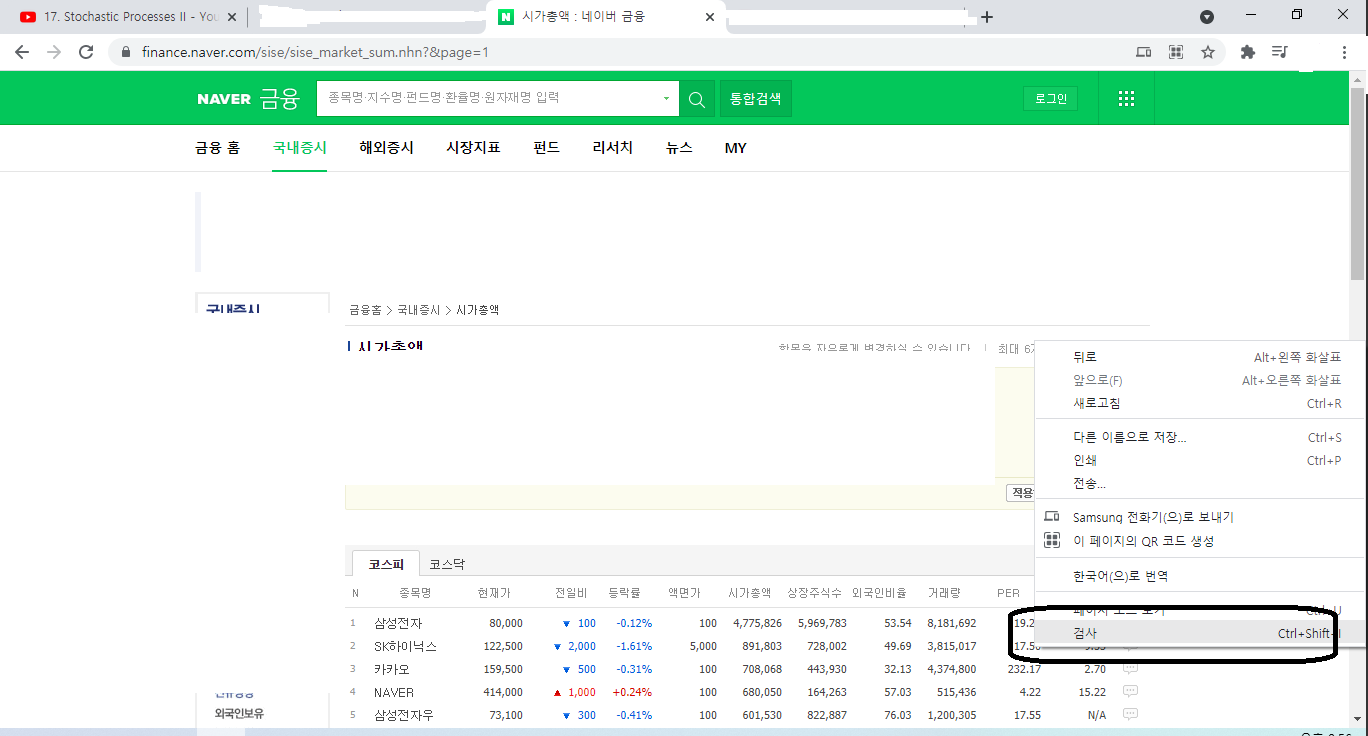
그림1: 익스플로러 검사 예시 개인적으로 구글 크롬을 쓰는데, 홈페이지에서 마우스 우클릭을 해서 "검사" 버튼을 누르면 무언가 추가적인 창이 생긴다. 그중 "Elements" 텝을 클릭해보면, 홈페이지가 어떻게 코딩되어 있는지 상세하게 나온다.
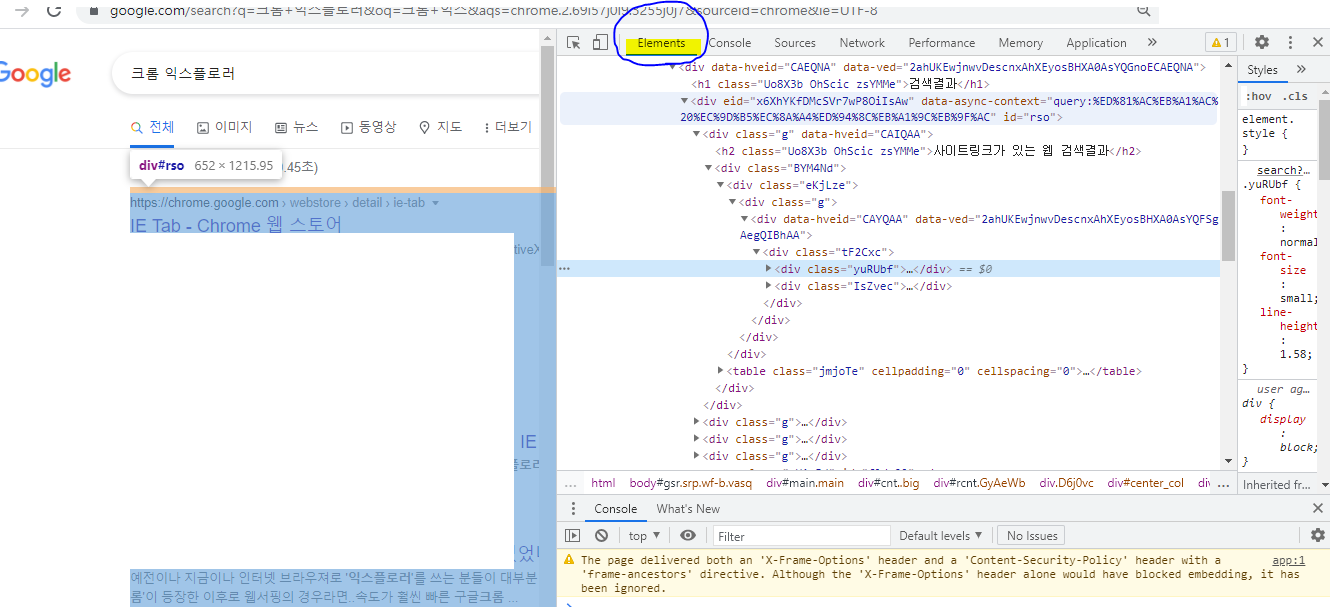
그림2: "검사"버튼 클릭 시 화면 예시 홈페이지 구조 파악
HTML 문서의 구조
웹데이터를 수집하기 위해서 홈페이지 코딩까지는 확인은 쉽게 할 수 있을 것이다. 하지만 이다음부터가 쉽지는 않다. 보통 홈페이지 하나에 몇 천 줄 되는 코딩을 언제 다 분석해서 확인하고 내가 필요한 데이터를 뽑을 수 있다는 말일까? 여기에서 HTML 문서의 구조만 알면 의외로 쉽게 접근할 수 있다.
모든 HTML 문서는 아래와 같은 구조로 되어 있다.
<HTML> <HEAD> 앞에 미리 빼 두는 내용, 홈페이지 상단 내용, 제목 등 </HEAD> <BODY> 본문, 실제 상세한 데이터 </BODY> </HTML>우리가 특정 기사 제목이나 핵심만 뽑아내는 것이 목적이라면, HEAD 부분을 집중적으로 볼 필요가 있고, 실제 데이터가 필요하다면, BODY를 집중적으로 볼 필요가 있다. ( 물론 BODY는 세부적으로 또 여러 문단으로 나뉘어 있다고 생각하면 된다. ) 즉, HTML 문서가 코드로 이루어져 있다고 겁먹을 필요없이 일반적인 글처럼 서론-본론(본문1-본문2...) 등으로 나뉘어져 있다고 생각하면 된다.
tag를 이용한 필요 데이터 확인

그림3: Elements 태그 확인 모든 HTML 문장에는 TAG가 달려있다. "<tag> 홈페이지에서 보이는 부분 </tag>" 이렇게 끝나는데, 이 tag는 홈페이지 특정 구성 요소의 고유한 성분 같은 것이다. 우리의 목적은 홈페이지를 만드는 것이 아니니 다양한 tag들이 무엇을 의미하는지는 알 필요가 없다. 우리가 찾고자 하는 내용에 어떤 tag를 달고 있는지이다. 그림 3에 표시된 것처럼 "검사"를 누르고 해당 버튼을 누른 뒤 홈페이지 각 부분을 클릭하면, 홈페이지의 구성요소가 어떤 tag를 갖고 있는지 다 찾아준다.
tag를 이용한 네이버 파이낸스 구조 파악
위 개념을 바탕으로 우리는 네이버 파이낸스에서 주식 데이터를 뽑아내는 웹스크래핑 작업을 수행할 수 있다. 아래 네이버파이낸스 주소에 들어가서 우리가 찾고 싶은 주식명, 종가 등의 데이터가 어떤 tag 즉, 어떤 고유한 특성을 갖고 있는지를 찾아보자.
https://finance.naver.com/sise/sise_market_sum.nhn?&page=1
그림 3에서 소개한 기능을 이용해서 잘 찾아보면, 홈페이지 하단의 주식 데이터는 "tbody"라는 대목차 밑에 "tr"이라는 tag를 달고 있으며, 상세 데이터 앞에는 "td"라는 tag를 달고 있는 것을 알 수 있을 것이다. 우리는 이 tag들이 무엇을 의미하는지 무슨 기능을 하는지 알 필요가 없다. 중요한 것은 우리가 원하는 데이터가 "tbody"-"tr"-"td"로 이어지는 공통적인 성격을 갖고 있다는 뜻이다. 이제 웹스크래핑을 위해서 할 일은 사람들 모여있는 곳에서 "안경 쓴 사람 모여~~~" 하듯이 위 tag를 갖고 있는 데이터를 모으는 일이다.
반응형'금융퀀트 > 프로그램기초' 카테고리의 다른 글
파이썬 : 데이터 형식(&Pandas 데이터) (0) 2021.07.05 파이썬 : 웹스크레핑 Beautiful Soup 라이브러리 (0) 2021.07.04 파이썬 : 가상환경 구축 (Windows) (0) 2021.06.03 파이썬 라이브러리 설치(Windows) (0) 2021.06.03 아나콘다, 파이썬, 비주얼 스튜디오 사용(Windows) (0) 2021.06.03