-
PER PBR 활용01 : PER PBR 데이터 입수(파이썬)금융퀀트/(퀀트)PERPBR활용 2023. 5. 30. 07:33반응형
PER과 PBR의 개념
PER과 PBR은 현재 기업의 주식이 거래되는 가격을 기업의 근본가치를 나타내는 지표들(주당 순이익, 주당 순자산가치)로 나눠준 것이다. PER과 PBR의 사용 방법: 산업별 비교에서도 강조한 것처럼 PER PBR은 그 숫자 자체가 절대적인 의미를 갖는 것은 아니다. 중요한 것은 산업별 PER, PBR과 비교하는 것으로 특정 기업이 속해있는 산업의 PER, PBR에 비해서 높은 PER, PBR을 가졌는지를 분석하는 것이 의미 있다.
현재 산업별 PER, PBR을 제공해 주는 곳은 네이버증권, KRX, 각 증권사의 HTS, MTS 정도이다. 각 제공처마다 제공하는 "산업별" PER, PBR의 "산업별" 분류가 다르고, 일괄 제공되는 데이터다 보니 필요 없는 정보도 많다. 직접 산업별 PER, PBR 데이터를 만들어볼 수는 없을까?
PER과 PBR 데이터 찾기: 네이버 증권(https://finance.naver.com/)
산업별 PER과 PBR을 구하기 위해서는 먼저, 기업별 PER, PBR 데이터를 모아야 한다. 네이버 증권에서 "기업은행"을 치고 들어가면 아래 그림 1과 같은 화면이 나온다.

그림1: 네이버 주식 PER, PBR 데이터 네이버 주식 홈페이지에서 그림 1에 표시한 위치에 PER, PBR 데이터를 제공하고 있는 것이다. 그리고 URL 은 아래 그림 2에 구분해 놓은 것처럼 "finance.naver.com/item/main.naver?code=" 부분과 "024110"이라는 주식종목코드로 구성되어 있다.

그림2 네이버 증권 종목검색 URL 구성 PER과 PBR 데이터 입수
python으로 네이버 증권 홈페이지에서 PER, PBR 데이터를 불러오려면 request, Beautifulsoup 라이브러리를 사용하면 된다. request 라이브러리를 통해 홈페이에 정보를 요청하고 Beautifulsoup 라이브러리를 통해 응답받은 정보를 처리하는 과정을 거치는 것이다. request를 통해서 페이지 정보를 받으면 PER과 PBR의 위치를 파악하는 것이 중요한데, 아래 그림 3처럼 브라우저의 "검사" 기능을 이용해서 HTML 문서에서 데이터의 위치를 파악하는 것이 가능하다.

그림3: "검사" 기능과 HTML element 확인 찾은 데이터의 좌표까지 파악해야 비로소 홈페이지의 데이터를 사용할 수 있게 된다. 아래 그림 4처럼 데이터의 Copy selector를 하면 데이터의 좌표가 복사된다. 홈페이지의 PER, PBR을 복사하면 "#_per", "#_pbr"과 같이 나올 텐데 아래 코드 예시처럼 select_one이라는 함수를 써서 PER, PBR 값을 갖다 쓰면 된다.
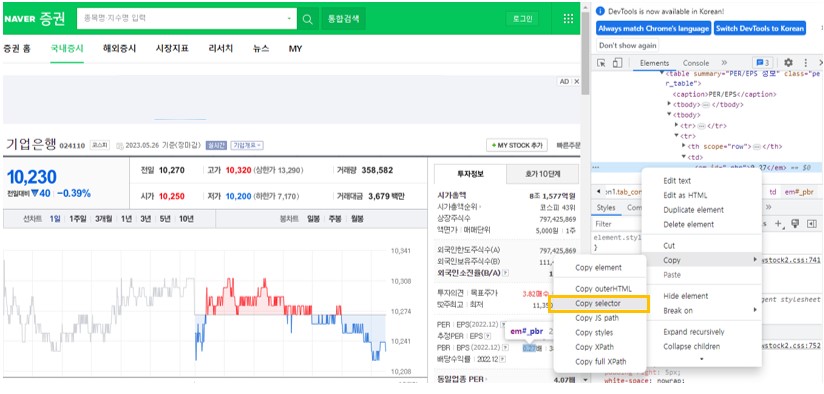
그림4: selector 의 path 복사 PER, PBR 데이터 GET 함수 생성
홈페이지에서 종목코드별로 PER, PBR 데이터를 제공하므로, 종목코드를 넣으면 PER, PBR 값이 나오는 함수가 필요하다. 아래는 종목코드를 변수로 받는 getPerPbr이라는 함수의 예시이다.
import pandas as pd from bs4 import BeautifulSoup import requests # getPerPbr이라는 함수 생성 입력변수는 주식종목코드 def getPerPbr(stcode): # 빈 데이터 프레임 만들기 df = [] # request 를 보낼 url 구성: 기본URL + 종목코드 url = "https://finance.naver.com/item/main.naver?code={}".format(stcode) # 해당 url 로 정보 요청 res = requests.get(url) # 받은 정보를 soup 에 저장 soup = BeautifulSoup(res.text, "lxml") # PER, PBR 값을 입수 n/a 인 경우에는 0으로 처리 try: per = soup.select_one("#_per").text except AttributeError: per = 0 try: pbr = soup.select_one("#_pbr").text except AttributeError: pbr = 0 # 입수된 정보를 전부 df_if 라는 list 에 저장 df_if = [stcode, per, pbr] # df에 df_if 값을 추가 df.append(df_if) # 최종 DataFrame 값 출력 df = pd.DataFrame(df, columns=['code', 'per', 'pbr']) return df if __name__ == "__main__": # getPerPbr이라는 함수에 종목코드 "000150"을 넣어서 결과값 입수 df = getPerPbr("000150") # 입수된 결과값 PRINT print(df)위 코드를 실행해 보면 아래와 같이 홈페이지와 똑같은 데이터가 입수되는 것을 확인할 수 있다.(n/a값은 0으로 처리된다.) 아래 예시는 두산(000150)의 PER, PBR 입수 예시이다.
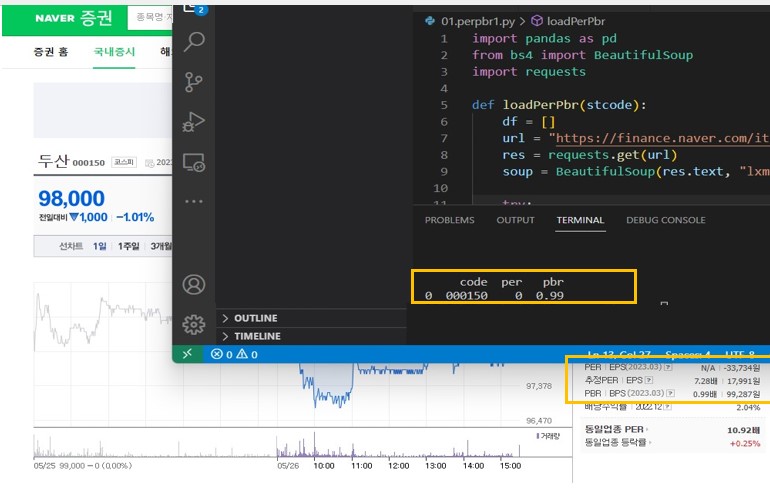
그림5 per, pbr 데이터 확인 반응형'금융퀀트 > (퀀트)PERPBR활용' 카테고리의 다른 글
PER PBR 활용06 : 기업별 산업코드 PER PBR 데이터 생성 프로그램 CLASS 구성 (0) 2023.06.10 PER PBR 활용05 : DART기업고유번호매핑 및 산업코드 매핑 (2) 2023.06.03 PER PBR 활용04 : 주식 종목 산업분류 데이터 받아오기(DART API) (0) 2023.06.02 PER PBR 활용03 : 주식별 PER PBR 목록 만들기 (0) 2023.06.01 PER PBR 활용02 : 주식목록 입수(공공데이터API) (0) 2023.05.31