-
파이썬 : 웹스크레핑 네이버 파이낸스 데이터수집금융퀀트/프로그램기초 2021. 7. 15. 00:58반응형
BeautifulSoup 함수 사용
find/find_all 함수
앞서 글에서 ( "02 웹 스크레 핑: Beautiful Soup 라이브러리" 참조 ) 우리는 Beautiful Soup으로 뽑아낸 네이버 파이낸스 데이터를 soup이라는 인스턴스에 넣었다. 이 인스턴스에 Beautiful Soup에서 제공하는 다양한 함수들을 넣어서 필요한 값을 찾을 수 있다. 우리가 지금 네이버 파이낸스 데이터를 수집하기 위해 필요한 함수는 find, find_all, get_text 정도이다.
find 함수는 아래 예시의 첫 번째 줄로 설명하면 "table"이란 태그를 가진 것 중 최초 검색 결과를 가져온다. 여기에 attributes(attrs)라는 상세 값을 주어서 검색을 더욱 정교화할 수 있는데 아래 예시의 두 번째 줄에서는 "table" 태그를 가진 것 중 "class"가 "type_2"인 것을 찾으라는 것이 된다. find_all은 해당 태그를 가진 모든 것을 찾으라는 명령어이다.
soup.find("table") soup.find("table", attrs={"class":"type_2"}) soup.find_all("th")get_text 함수
k = soup.find("table", attrs={"class":"type_2"}).find("tr") k = k.get_text() print(k)위는 get_text의 사용 예시이다. soup에서 지금까지 익힌 find 함수를 통해서 "tr" 태그가 달린 부분을 찾은 다음 그것을 k라는 인스턴스에 통째로 넣었다. 그 인스턴스에 대해서 get_text()를 하면, 해당 부분에 붙어있었던 태그들이 모두 사라지고 순수하게 해당 부분의 텍스트만 남는다.
주식 데이터 추출
지금까지 " 02 웹 스크레 핑: 홈페이지 구조 파악(네이버 파이낸스) ", " 02 웹 스크레 핑: Beautiful Soup 라이브러리 " 및 Beautiful Soup 합수를 사용하여 아래와 같은 코드로 네이버 파이낸스 페이지 1의 주식 데이터를 확인해 볼 수 있다.
import requests from bs4 import BeautifulSoup import pandas as pd url="https://finance.naver.com/sise/sise_market_sum.nhn?&page=1" site_text = requests.get(url) soup = BeautifulSoup(site_text.text, "lxml") data_rows = soup.find("table", attrs={"class":"type_2"}).find("tbody").find_all("tr") #tr tag를 갖고있는 묶음들을 data_rows 인스턴스로 선언 for data_row in data_rows: #각각의 data_rows를 data_row 변수에 입력 data = [] #data list 형식을 선언 data_columns = data_row.find_all("td") #td tag를 갖고 있는 데이터를 data_columns로 선언 if len(data_columns) == 1: #data_columns 값 공란 즉, data길이가 1인 것 제외 continue for data_column in data_columns: #data_columns를 data_column 변수에 입력 data.append(data_column.get_text().strip()) #위에서 선언한 data list에 column 값 추가 print(data) #결과값 print일일 전체 주식 데이터 추출
홈페이지 구조 파악
지금까지는 아래 홈페이지의 "page 1"의 데이터만 불러왔다. 하지만 우리가 주식 봇을 만들기 위해서 필요한 것은 그때그때의 모든 주식의 가격이다.
https://finance.naver.com/sise/sise_market_sum.nhn?&page=1
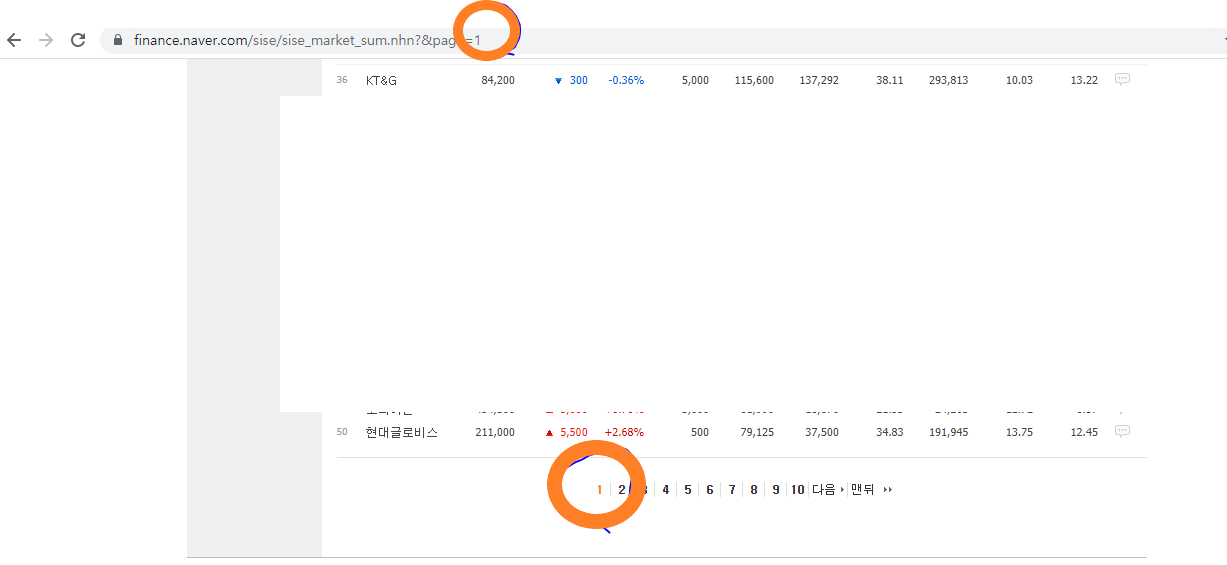
그림1: 네이버파이낸스 홈페이지 구조 위 네이버 파이낸스 홈페이지 주소를 보면 URL의 page 번호가 아래 목록의 조회 번호를 따라간다는 것을 알 수 있다. 우리는 하단의 맨뒤 목록번호만 알아낸다면, 1 page 부터 맨 마지막 page까지의 반복 작업을 통해서 네이버 파이낸스에 "국내 증시 시가총액" 화면에 제시된 모든 주식 정보를 받아볼 수 있다.
최대 페이지수 구하기
pagelist = soup.find("table",attrs={"class":"Nnavi"}).find("td", attrs={"class":"pgRR"}).a["href"] # 홈페이지 아래쪽 하단을 번호를 통해서 목록의 맨 마지막 숫자를 나타내는 태그내용 입수 maxpage = int(str(pagelist[pagelist.find("=")+1:])) # 구조가 <a href="/sise/sise_market_sum.nhn?&page=32"> 이니까 # "="가 있는 위치 다음 칸부터 전부가 마지막 페이지를 의미하며, 이를 숫자형(int)으로 변경검사기능을 잘 사용하면 page 최대 번호는 pagelist 인스턴스를 정의한 tag를 통해서 찾을 수 있다. 문제는 pagelist 번호는 href tag 안에 있다는 것이다. 그래서 최대 페이지수(maxpage)를 구할 때, tag안에 등호("=")가 있는 문자열의 위치 다음칸부터 마지막까지의 숫자를 찾아내면 된다.
예를 들면, a href="/sise/sise_market_sum.nhn?&page=327" 이면 등호("=")가 있는 다음 문자열에 3이 있고 그 뒤부터 끝까지 읽어내면, 27을 더 읽어내서 327이라는 최대 페이지를 나타내는 문자열을 만들 수 있는 것이다.
전체 주식 데이터 추출
import requests from bs4 import BeautifulSoup import pandas as pd # soup 인스턴스에 page 1 의 정보를 저장 url="https://finance.naver.com/sise/sise_market_sum.nhn?&page=1" site_text = requests.get(url) soup = BeautifulSoup(site_text.text, "lxml") # soup 인스턴스 이용해 최대페이지 수 구하는 부분: 최대 페이지를 maxpage 인스턴스에 저장 pagelist = soup.find("table",attrs={"class":"Nnavi"}).find("td", attrs={"class":"pgRR"}).a["href"] maxpage = int(str(pagelist[pagelist.find("=")+1:])) for pages in range(1,maxpage): # 1 페이지부터 maxpage까지 사이트 검토 url="https://finance.naver.com/sise/sise_market_sum.nhn?&page={}".format(str(pages)) site_text = requests.get(url, headers=headers) soup = BeautifulSoup(site_text.text, "lxml") data_rows = soup.find("table", attrs={"class":"type_2"}).find("tbody").find_all("tr") for data_row in data_rows: data = [] # data list 형식을 선언 data_columns = data_row.find_all("td") #td tag를 갖고 있는 데이터를 data_columns로 선언 if len(data_columns) == 1: #data_columns 값 공란 즉, data길이가 1인 것 제외 continue for data_column in data_columns: #data_columns를 data_column 변수에 입력 data.append(data_column.get_text().strip()) #위에서 선언한 data list에 column 값 추가 print(data) #결과값 print반응형'금융퀀트 > 프로그램기초' 카테고리의 다른 글
MYSQL : Python 웹스크레핑 데이터 MySQL 서버 저장하기 (0) 2022.08.27 MYSQL 설치(Windows) (1) 2022.08.24 파이썬 : 데이터 형식(&Pandas 데이터) (0) 2021.07.05 파이썬 : 웹스크레핑 Beautiful Soup 라이브러리 (0) 2021.07.04 파이썬 : 웹스크레핑 홈페이지 구조파악(네이버파이낸스) (0) 2021.07.04